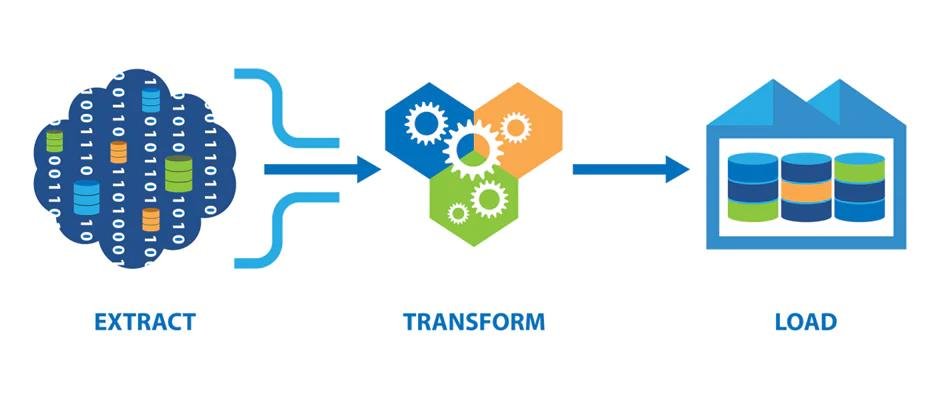
In the era of big data, enterprises face the daunting challenge of efficiently managing vast amounts of information that flow through their systems daily. The ETL (Extract, Transform, Load) process is crucial in this context, as it dictates how data is collected, transformed, and delivered for analysis. As businesses seek innovative solutions to these challenges, many are turning to platforms like Databricks for ETL to streamline and enhance their data workflows. Optimizing ETL processes is essential for handling big data, improving data quality, and reducing processing times, ultimately enhancing an organization’s data management and analytics capabilities.
The Importance of ETL Optimization
ETL processes are the backbone of data integration and analysis in enterprises. As data volumes grow exponentially, optimizing ETL becomes imperative to ensure that businesses can process information quickly and accurately. Effective ETL optimization leads to:
- Improved Data Quality. Ensures that data is clean, accurate, and consistent, which is critical for reliable analytics and decision-making.
- Reduced Processing Time. Speeds up data processing, enabling faster insights and more timely decision responses.
- Cost Efficiency. Minimizes the use of resources, reducing operational costs associated with data handling.
Key ETL Optimization Techniques
Parallel processing involves executing multiple ETL tasks simultaneously rather than sequentially. This technique significantly reduces processing time by leveraging multi-core processors and distributed computing environments. By breaking down tasks into smaller, concurrent units, enterprises can maximize resource utilization and improve throughput.
Incremental Loading
Incremental loading is the process of updating only the data that has changed since the last ETL run, rather than reprocessing the entire dataset. This approach reduces the amount of data to be processed and transferred, leading to faster ETL cycles and reduced resource consumption. It also minimizes the impact on system performance and ensures data freshness.
Data Partitioning
Partitioning divides large datasets into smaller, more manageable segments, allowing for more efficient processing and retrieval. By processing partitions independently, ETL systems can optimize resource allocation and reduce processing times. Partitioning can be based on criteria such as date ranges, geographical regions, or other logical divisions relevant to the business.
Role of Automation and Monitoring Tools
Automation is critical in streamlining ETL processes, reducing manual intervention, and minimizing errors. Automated ETL workflows can be scheduled to run at optimal times, ensuring that data is processed without delays. Additionally, automation tools can adapt to changing data structures and requirements, providing flexibility and scalability.
Monitoring tools play a vital role in ETL optimization by providing real-time insights into the performance of ETL processes. These tools help identify bottlenecks, track resource usage, and detect anomalies, enabling proactive management and troubleshooting. By leveraging monitoring tools, enterprises can ensure consistent ETL performance and maintain data integrity.

Conclusion
As enterprises continue to grapple with the complexities of big data, optimizing ETL processes becomes a strategic necessity. By adopting techniques such as parallel processing, incremental loading, and data partitioning, organizations can enhance their ETL efficiency, improve data quality, and reduce processing times. Incorporating automation and monitoring tools further augments these efforts, ensuring robust and reliable data management.
Enterprises are encouraged to embrace these ETL optimization techniques to unlock the full potential of their data and drive better business outcomes. By doing so, they can position themselves to take advantage of emerging opportunities in data analytics, gain valuable insights, and maintain a competitive edge in their respective industries











{kind=link}